Abstract
A darknet market is an online marketplace typically implemented over Tor, where vendors sell illegal products or criminal services. Due to dramatic growth in the popularity of such markets, there is a recognized need for automatic investigation of the market’s ecosystem and identification of anonymous vendors. However, as they often create multiple accounts (or Sybil accounts) within or across different marketplaces, detecting Sybil accounts becomes the key to understanding the ecosystem of darknet markets and identifying the actual relationship between the vendors. This study presents a novel Sybil detection method that extracts multiple features of vendors from photographs in a fine-grained level (e.g., image similarity, main category, subcategory, and text data), and reveals the multiple Sybil accounts of them simultaneously. Each feature is extracted from multiple rich sources using an image hash algorithm, Deep Neural Network (DNN) classifier, image restoration, and text recognition tool; and merged using a weighted feature embedding model. The matching score of each vendor is then calculated to identify not only the exact Sybil accounts, but multiple potential accounts suspected of being associated to a single operator. We evaluate the efficacy of our method using real-world datasets from four large darknet markets (i.e., SilkRoad2, Agora, Evolution, Alphabay) from 2014 to 2015. Because of the anonymity of darknet market, we construct the ground-truth of Sybil accounts by randomly splitting the dataset of vendors into two even parts. We used the first set to train the model, and linked the second set to the original vendor in the first set to evaluate performance. Our experimental results demonstrated that the proposed method outperforms the existing photography-based system with an accuracy of 98%, identifying up to 700% more candidate Sybil accounts than prior work. Additionally, our method detects multiple Sybil accounts for 90% of evaluated test cases, presenting a very different picture of darknet
Overview of the proposed method
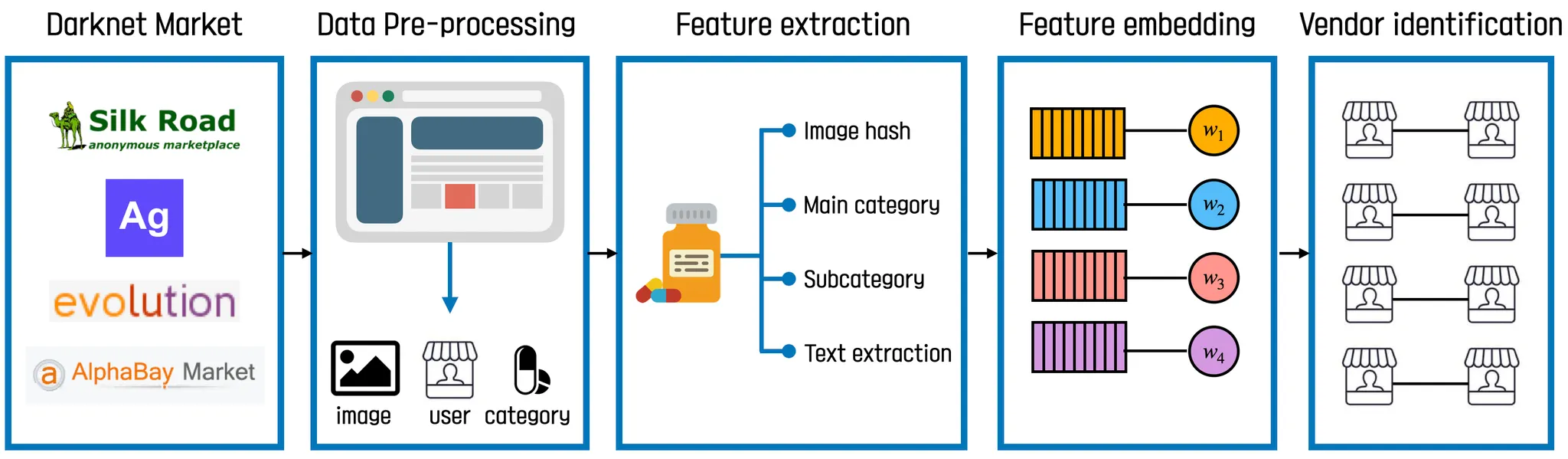
First, a data is pre-processed to extract meaningful information from the crawled dataset such as the ID, product image, product category, and PGP key of each vendor. Second, four main features such as image similarity, main category, subcategory, and text data from photos are extracted, and similarity scores are calculated between vendors. Third, all of these features are merged using a weighted feature embedding model. Finally, the connectivity of vendors with different accounts is identified using the final similarity scores, and candidate vendors are suggested as well.
Feature extraction and embedding
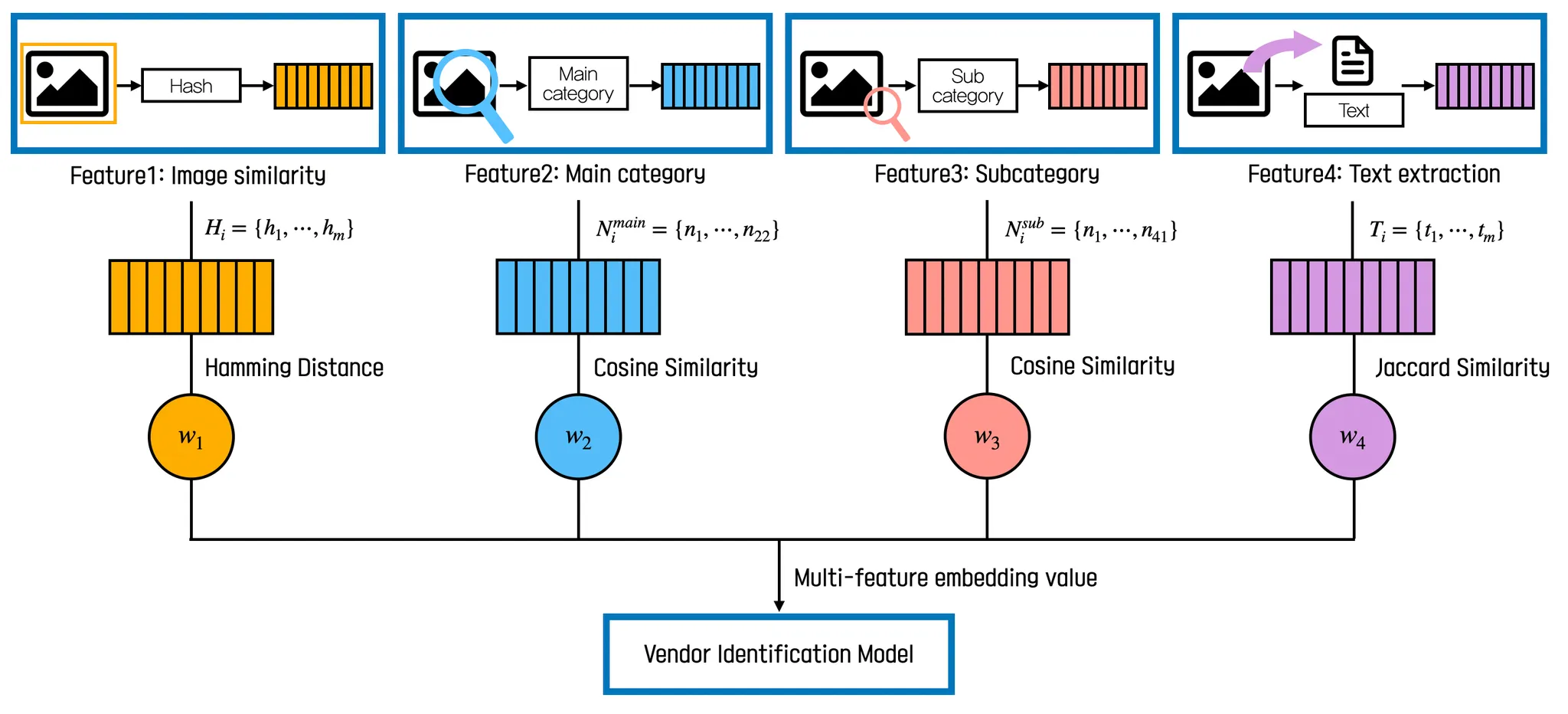
After extracting features from a photograph, the similarity scores of each feature are used to calculate the final scores for the vendor by applying weighted feature embedding method which sets weight for each feature’s , where represents the similarity score of feature.
Result
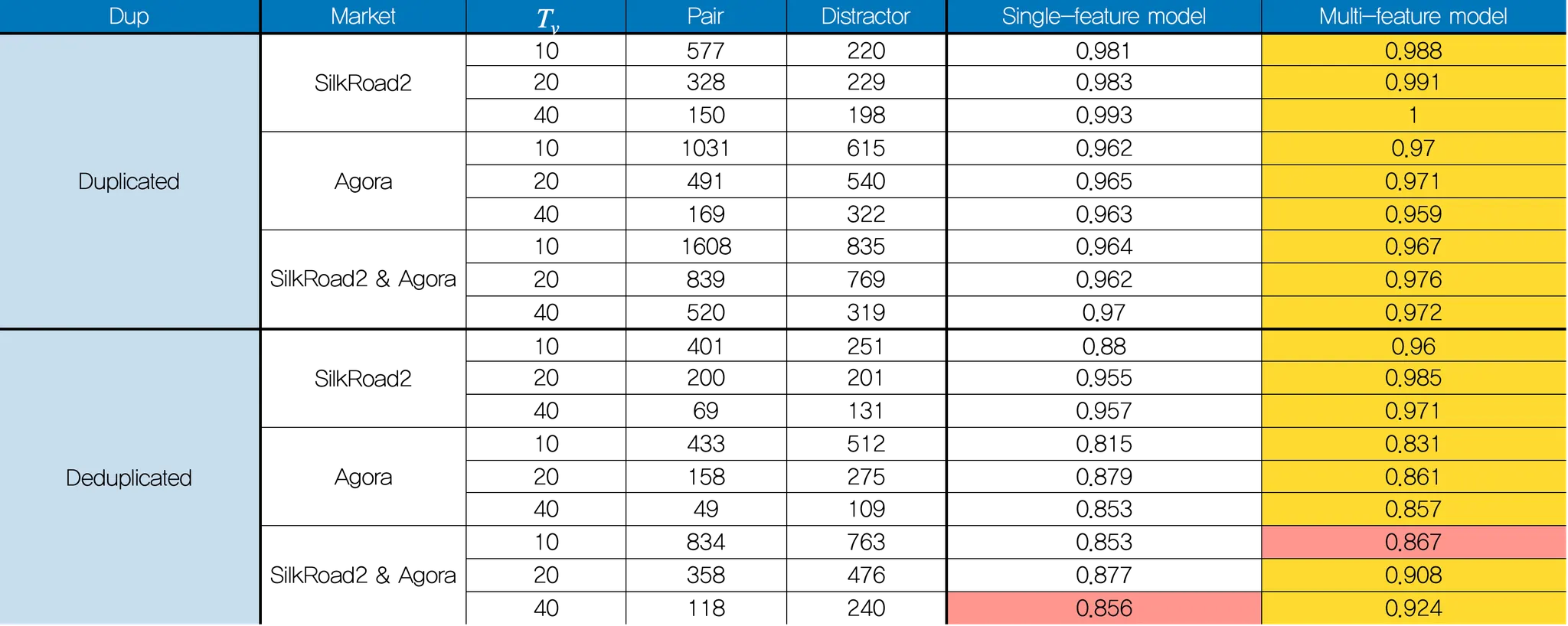
We set only the vendors with the same PGP key as an identical vendor and split the dataset of given vendors into two pseudo pairs for constructing the dataset of Sybil pairs. For testing the feasibility of re-identifying vendors based on their features extracted by our method, we create two versions of the ground-truth dataset to show that our model does not just match the same photos in a naive way. Each product’s picture was counted once, and we allowed different products to use the same image. For the duplication version, we consider all of the vendor’s photos (potentially including duplicates). For the deduplicated version, we remove all of the duplicated photos that are used for different products by using their base64 values for the duplicate check.
As shown in the table, accuracy rate of our method is remarkably high especially in deduplicated datasets compared to the single feature case. The single feature model also achieved high accuracy when duplicated images were allowed, but it dropped when duplicated data were removed. This indicates that the single feature model’s high accuracy seems to be the result of matching duplicated images, rather than actually capturing vendors’ unique photography styles. Furthermore, single feature model is more limited in its coverage. In the comparison results, it can be seen that ResNet-50 model returns the highest accuracy for after removing duplicated images. However, it is still not as accurate as our model with . Our model with a lower threshold () outperforms the single-feature model with a higher threshold (). It implies that our model covers up to 700% more vendors than the previous research and achieves higher matching accuracy even though there may not be enough training data for each vendor. The advantage is more meaningful when duplicated images are removed.